
AAAI2023 Artificial Intelligence for Education
This year, the AI4Edu workshop is co-located with the main AAAI 2023 conference in Washington DC, USA on Feb 13, 2023. We encourage offline participation and will also provide online option. Hotel and travel info can be found here.
UPDATES
- Workshop Registration: Registration is available at https://aaaiconf.cventevents.com/AAAI23. To participate in this workshop, the Workshop Only registration type is enough. For nontechnical regular registrants, the 1-day early bird and normal price are $250 and $350 respectively, and for students, $150 and $200 respectively. Prices about technical registrants discount and 2-day can be found at https://aaai.org/Conferences/AAAI-23/registration/.
Workshop Schedule
The AI4Edu workshop is co-located with the main AAAI 2023 conference in Washington DC, USA on Feb 13, 2023. All the time slots are in EST (New York local time).
-
09:00 - 09:10 Opening
- 09:10 - 10:00 [Keynote Talk] Where Can AI Take Education by 2030, Tom Mitchell, School of Computer Science, Carnegie Mellon University
- 10:00 - 10:50 [Keynote Talk] From Autonomy to Synergy: Envisioning Next Generation Human-AI Partnerships, Sidney D’Mello, Institute of Cognitive Science and the Department of Computer Science, University of Colorado Boulder.
-
10:50 - 11:00 Break
- 11:00 - 11:15 Summary and Winner Announcement of the AAAI2023 Global Knowledge Tracing Challenge
- 11:15 - 11:30 [Winning Solution Presentation] 3rd Effective Information Extraction of Time Series for Knowledge Tracing, Xing Jiang
- 11:30 - 11:45 [Winning Solution Presentation] 2nd Effective Use of Sequence Models for Knowledge Tracing, Guimei Liu, Huijing Zhan
- 11:45 - 12:00 [Winning Solution Presentation] 1st Attention-based Knowledge Tracing with Rich Interaction Representations, Shuanghong Shen, Sailan Hu, Bihan Xu, Zhenya Huang, Qi Liu, Enhong Chen
-
12:00 - 13:15 Lunch
- 13:15 - 13:30 [Cross-submission Presentation] Transition-Aware Multi-Activity Knowledge Tracing, Siqian Zhao, Chunpai Wang and Shaghayegh Sahebi. The 2022 IEEE International Conference on Big Data (BigData 2022)
- 13:30 - 13:45 [Cross-submission Presentation] pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models. Zitao Liu, Qiongqiong Liu, Jiahao Chen, Shuyan Huang, Jiliang Tang, Weiqi Luo. The 36th Conference on Neural Information Processing Systems (NeurIPS 2022) Datasets and Benchmarks Track
- 13:45 - 14:00 [Cross-submission Presentation] Evaluating the Explainers: Black-Box Explainable Machine Learning for Student Success Prediction in MOOCs. Vinitra Swamy, Bahar Radmehr, Natasa Krco, Mirko Marras, Tanja Käser. The 15th International Conference on Educational Data Mining (EDM 2022)
- 14:00 - 14:15 [Cross-submission Presentation] Meta Transfer Learning for Early Success Prediction in MOOCs. Vinitra Swamy, Mirko Marras, Tanja Käser. The 2022 ACM Conference on Learning at Scale (L@S 2022)
- 14:15 - 14:30 [Cross-submission Presentation] Code-DKT: A Code-based Knowledge Tracing Model for Programming Tasks. Yang Shi, Min Chi, Tiffany Barnes, Thomas Price. The 15th International Conference on Educational Data Mining (EDM 2022)
-
14:30 - 14:40 Break
- 14:40 - 14:50 [Paper Presentation] Tongwen Huang, Xihua Li and Yi Chao. Finding Similar Exercises in Retrieval Manner
- 14:50 - 15:00 [Paper Presentation] He Zhu, Xihua Li, Xuemin Zhao, Yunbo Cao and Shan Yu. TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
- 15:00 - 15:10 [Paper Presentation] Fang Nan, Feng Tian, Yaozhi Wang, Qidong Liu, Yanze Wu, Jizhong Zhang, Huan Li, Haiping Zhu, Yuzhe Yao, Heng Zhang, Yaqiang Wu and Qinghua Zheng. Inferring Actions and Joint Attention From Dual-view Classroom Videos
- 15:10 - 15:20 [Paper Presentation] Anup Shakya, Vasile Rus and Deepak Venugopal. Mastery Guided Non-parametric Clustering to Scale-up Strategy Prediction
- 15:20 - 15:30 [Paper Presentation] Tim Klausmann, Marius Köppel, Daniel Schunk and Isabell Zipperle. Can machine learning solve the challenge of adaptive learning and the individualization of learning paths? A field experiment in an online learning platform
- 15:30 - 15:40 [Paper Presentation] John Stamper, Bharat Gaind, Karun Thankachan, Huy Nguyen, Steven Moore. Hierarchical Concept Map Generation from Course Data
- Paper PDF Link
- 15:40 - 15:50 [Paper Presentation] Hyeondey Kim, Jinwoo Nam, Minjae Lee, Yun Jegal, Kyungwoo Song. Leveraging Skill-to-Skill Supervision for Knowledge Tracing
- 15:50 - 16:00 [Paper Presentation] Alexander Jenkins, Imad Jaimoukha, Ljubisa Stankovic and Danilo Mandic. Fair and Skill-diverse Student Group Formation via Constrained K-way Graph Partitioning
- 16:00 - 16:10 [Paper Presentation] Xiaofei Zhou, Hanjia Lyu, Jiebo Luo and Zhen Bai. ML-SD Modeling: How Machine Learning Can Support Scientific Discovery Learning for K-12 STEM Education
- 16:10 - 16:20 [Paper Presentation] Vishesh Kalvakurthi, Aparna Varde and John Jenq. Hey Dona! Can you help me with student course registration?
- 16:20 - 16:30 [Paper Presentation] Roberto Daza, Luis F. Gomez, Aythami Morales, Ruben Tolosana, Julian Fierrez, Ruth Cobos and Javier Ortega-Garcia. MATT: Multimodal Attention Level Estimation for e-learning Platforms
- 16:30 - 16:40 [Paper Presentation] Jia Tracy Shen and Dongwon Lee. Imputing Knowledge Tracing Data with Subject-Based Training via LSTM Variational Autoencoders
- 16:40 - 16:50 [Paper Presentation] Levi Corallo and Aparna Varde. Optical Character Recognition and Transcription of Berber Signs from Images in a Low-Resource Language Amazigh
- 16:50 - 17:00 [Paper Presentation] Frederik Baucks, Robin Schmucker and Laurenz Wiskott. Tracing Changes in University Course Difficulty Using Item-Response Theory
Program Details
Keynote Talks
Where Can AI Take Education by 2030
Tom Mitchell, School of Computer Science, Carnegie Mellon University
Abstract: The past decade has put us in a unique position with respect to AI and Education: AI has made surprisingly rapid progress, while the use of computers in education has finally become mainstream. The thesis of this talk is that if there is ever going to be a decade in which AI revolutionizes education, it will be the coming decade. We'll look at the state of the art, and speculate where this could lead us during the 2020's, in three distinct areas: (1) educational settings where single students interact with single computers, (2) settings where the interaction involves a student-computer-teacher triangle, and (3) settings where students work in teams with an AI assistant also present. This talk may well raise more questions than it answers, so we'll leave plenty of time for discussion.
Bio: Tom M. Mitchell is the Founders University Professor at Carnegie Mellon University, where he founded the world's first Machine Learning Department. His research interests range include machine learning, artificial intelligence, cognitive neuroscience, and the impact of AI on society. His current focus is AI and education, where he has worked closely with organizations that field computer learning environments to millions of students, including Squirrel AI, and CK12.org. He has testified to the U.S. Congressional Research Service, and the U.S. House Subcommittee on Veterans' Affairs regarding potential uses and impacts of artificial intelligence, and is currently co-chairing a U.S. National Academies study on AI and the future of work. Mitchell is an elected member of the U.S. National Academy of Engineering, and the American Academy of Arts and Sciences, and a Fellow and Past President of the Association for the Advancement of Artificial Intelligence (AAAI).From Autonomy to Synergy: Envisioning Next Generation Human-AI Partnerships
Sidney K. D’Mello, University of Colorado Boulder
Abstract: I'll describe a vision for AI, beyond a cold, autonomous agent working for humans to a socio-technical synergistic partnership with humans. I'll highlight these ideas in the context of the NSF National AI Institute for Student AI Teaming (www.isat.ai), which brings together a geographically distributed team of researchers with K-12 partners to reframe the role of AI in education, moving from a facilitator of personalized one-on-one learning, to a social, collaborative partner which helps students and teachers work and learn more effectively, engagingly, and equitably. The talk will highlight insights and technologies at the intersection of the Institute's three research strands: (1) foundational AI to understand and facilitate conversations; (2) orchestrating classroom interactions with AI; and (3) broadening participation with curriculum co-design. I'll contextualize the research within our commitment to responsible innovation and polycultural approaches for developing ethical AI technologies.
Bio: Sidney D'Mello (PhD in Computer Science) is a Professor in the Institute of Cognitive Science and Department of Computer Science at the University of Colorado Boulder. He is interested in the dynamic interplay between cognition and emotion while individuals and groups engage in complex real-world activities. He applies insights gleaned from this basic research program to develop intelligent technologies that help people achieve to their fullest potential by coordinating what they think and feel with what they know and do. D'Mello has co-edited seven books and has published more than 300 journal papers, book chapters, and conference proceedings. His research has received 17 awards at international conferences and has been funded by numerous grants. D'Mello serves(d) as Associate Editor and on the Editorial Boards of 11 journals. He leads the NSF National Institute for Student-Agent Teaming (2020-2025), which aims to develop AI technologies to facilitate rich socio-collaborative learning experiences for all students. Winning Solution Presentations
Effective Information Extraction of Time Series for Knowledge Tracing
Xing Jiang
Abstract: We would introduce our 3rd place solution for AAAI 2023 Global Knowledge Tracing Challenge. Our solution is a tree model with some manual features and a little embedding features, which make full advantage of the gradient tree model. Besides, some ensemble methods are also used in our solution, such as different sets of features and different sets of parameters. And we also used methods like data augmentation and weight method to reach a higher score. The best single lightgbm model can reach 0.8153 on public leaderboard.Effective Use of Sequence Models for Knowledge Tracing
Guimei Liu, Huijing Zhan
Abstract: In this talk, we introduce our 2nd place solution for AAAI 2023 Global Knowledge Tracing Challenge. Our solution is an ensemble of predictions made by several model architectures using different feature sets under various hyper-parameter settings. Our base model architecture takes two sequences as inputs: a history sequence and a query sequence. The history sequence has class labels and it stores users’ historical performance. The class labels of the query sequence are to be predicted. We applied Transformer, LSTM, GRU, vanilla RNN, their components and combinations on the two sequences to construct several model architectures. We generated features to capture user experiences and forgetting behaviors and incorporated them via an embedding layer. The best single model in our experiments uses a standard Transformer and achieves an AUC of 0.8095 on public leaderboard.Attention-based Knowledge Tracing with Rich Interaction Representations
Shuanghong Shen, Sailan Hu, Bihan Xu, Zhenya Huang, Qi Liu, Enhong Chen
Abstract: We propose an effective solution for the AAAI2023 Global Knowledge Tracing Challenge, which is positioned in first place of this challenge. Specifically, we incorporate rich features (e.g., answering time, interval time, question length) for the interaction representation, and design an Attention-based Knowledge Tracing method to conduct the interaction sequence modeling. In our proposed methods, we utilize many effective strategies to improve the prediction precision, such as data augmentation, cross-attention mechanism, and weights redistribution. The code for the solutions is available at https://github.com/shshen-closer/disguerCross-submission Talks
Transition-Aware Multi-Activity Knowledge Tracing
Siqian Zhao, Chunpai Wang and Shaghayegh Sahebi
Abstract: Accurate modeling of student knowledge is essential for large-scale online learning systems that are increasingly used for student training. Knowledge tracing aims to model student knowledge state given the student's sequence of learning activities. Modern Knowledge tracing (KT) is usually formulated as a supervised sequence learning problem to predict students' future practice performance according to their past observed practice scores by summarizing student knowledge state as a set of evolving hidden variables. Because of this formulation, many current KT solutions are not fit for modeling student learning from non-assessed learning activities with no explicit feedback or score observation (e.g., watching video lectures that are not graded). Additionally, these models cannot explicitly represent the dynamics of knowledge transfer among different learning activities, particularly between the assessed (e.g., quizzes) and non-assessed (e.g., video lectures) learning activities. In this paper, we propose Transition-Aware Multi-activity Knowledge Tracing (TAMKOT), which models knowledge transfer between learning materials, in addition to student knowledge, when students transition between and within assessed and non-assessed learning materials. TAMKOT is formulated as a deep recurrent multi-activity learning model that explicitly learns knowledge transfer by activating and learning a set of knowledge transfer matrices, one for each transition type between student activities. Accordingly, our model allows for representing each material type in a different yet transferrable latent space while maintaining student knowledge in a shared space. We evaluate our model on three real-world publicly available datasets and demonstrate TAMKOT's capability in predicting student performance and modeling knowledge transfer.pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Zitao Liu, Qiongqiong Liu, Jiahao Chen, Shuyan Huang, Jiliang Tang, Weiqi Luo
Abstract: Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat unknown and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at this https URL. We welcome contributions from other research groups and practitioners.Evaluating the Explainers: Black-Box Explainable Machine Learning for Student Success Prediction in MOOCs
Vinitra Swamy, Bahar Radmehr, Natasa Krco, Mirko Marras, Tanja Käser
Abstract: Neural networks are ubiquitous in applied machine learning for education. Their pervasive success in predictive performance comes alongside a severe weakness, the lack of explainability of their decisions, especially relevant in human-centric fields. We implement five state-of-the-art methodologies for explaining black-box machine learning models (LIME, PermutationSHAP, KernelSHAP, DiCE, CEM) and examine the strengths of each approach on the downstream task of student performance prediction for five massive open online courses. Our experiments demonstrate that the families of explainers do not agree with each other on feature importance for the same Bidirectional LSTM models with the same representative set of students. We use Principal Component Analysis, Jensen-Shannon distance, and Spearman's rank-order correlation to quantitatively cross-examine explanations across methods and courses. Furthermore, we validate explainer performance across curriculum-based prerequisite relationships. Our results come to the concerning conclusion that the choice of explainer is an important decision and is in fact paramount to the interpretation of the predictive results, even more so than the course the model is trained on. Source code and models are released at https://github.com/epfl-ml4ed/evaluating-explainers.Meta Transfer Learning for Early Success Prediction in MOOCs
Vinitra Swamy, Mirko Marras, Tanja Käser
Abstract: Despite the increasing popularity of massive open online courses (MOOCs), many suffer from high dropout and low success rates. Early prediction of student success for targeted intervention is therefore essential to ensure no student is left behind in a course. There exists a large body of research in success prediction for MOOCs, focusing mainly on training models from scratch for individual courses. This setting is impractical in early success prediction as the performance of a student is only known at the end of the course. In this paper, we aim to create early success prediction models that can be transferred between MOOCs from different domains and topics. To do so, we present three novel strategies for transfer: 1) pre-training a model on a large set of diverse courses, 2) leveraging the pre-trained model by including meta information about courses, and 3) fine-tuning the model on previous course iterations. Our experiments on 26 MOOCs with over 145,000 combined enrollments and millions of interactions show that models combining interaction data and course information have comparable or better performance than models which have access to previous iterations of the course. With these models, we aim to effectively enable educators to warm-start their predictions for new and ongoing courses.A Code-based Knowledge Tracing Model for Programming Tasks
Yang Shi, Min Chi, Tiffany Barnes, Thomas Price
Abstract: Knowledge tracing (KT) models are a popular approach for predicting students' future performance at practice problems using their prior attempts. Though many innovations have been made in KT, most models including the state-of-the-art Deep KT (DKT) mainly leverage each student's response either as correct or incorrect, ignoring its content. In this work, we propose Code-based Deep Knowledge Tracing (Code-DKT), a model that uses an attention mechanism to automatically extract and select domain-specific code features to extend DKT. We compared the effectiveness of Code-DKT against Bayesian and Deep Knowledge Tracing (BKT and DKT) on a dataset from a class of 50 students attempting to solve 5 introductory programming assignments. Our results show that Code-DKT consistently outperforms DKT by 3.07-4.00% AUC across the 5 assignments, a comparable improvement to other state-of-the-art domain-general KT models over DKT. Finally, we analyze problem-specific performance through a set of case studies for one assignment to demonstrate when and how code features improve Code-DKT's predictions.Workshop Paper Presentations
Finding Similar Exercises in Retrieval Manner
Tongwen Huang, Xihua Li and Yi Chao
Abstract: When students make a mistake in an exercise, they can consolidate it by “similar exercises” which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define “similar exercises” as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the FSE problem (Finding similar exercises). In other papers, FSE focuses on ranking method, this paper will comprehensively introduce recall, ranking, re-rank, and define similar exercise more accurately. Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
He Zhu, Xihua Li, Xuemin Zhao, Yunbo Cao and Shan Yu
Abstract: Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which help the model to effectively learn the representation of questions. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions ↑2.02% and knowledge point prediction ↑7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.Inferring Actions and Joint Attention From Dual-view Classroom Videos
Fang Nan, Feng Tian, Yaozhi Wang, Qidong Liu, Yanze Wu, Jizhong Zhang, Huan Li, Haiping Zhu, Yuzhe Yao, Heng Zhang, Yaqiang Wu and Qinghua Zheng
Abstract: There is a handful of pedagogical studies on the assessment of in-classroom teaching quality that indicate that recognizing student/teacher actions in the classroom and their non-contact interaction is necessary. Although modern classrooms are often equipped with dual-view cameras, i.e., forward and backward, which is a widely applied CCTV installation solution, existing recognition methods of recognizing student/teacher actions and understanding their attentions confront two challenges, (i) the combination explosion of Multi-Human and Multi-Object in Classroom (MHMOC) scenes and (ii) the dual-view separation between teacher-oriented and student-oriented videos. In this paper, we propose a novel framework to precisely recognize the actions and interactions between teachers and students in dual-view camera settings. Accordingly, a pose-feature-based graph neural network HOI detection and a joint attention detection are proposed to address the challenge. Our proposed method is comprehensively evaluated against various state-of-the-art methods, and the result shows that our method significantly outperforms the baselines with improvements of 22.4%,60.5% and 74.1% on the mAP, AUC and L2 distance, respectively. Especially, a prototype system based on our research is already deployed in real-world applications.Mastery Guided Non-parametric Clustering to Scale-up Strategy Prediction
Anup Shakya, Vasile Rus and Deepak Venugopal
Abstract: Predicting the strategy (sequence of concepts) that a student is likely to use in problem-solving helps Adaptive Instructional Systems (AISs) better adapt themselves to different types of learners based on their learning abilities. This can lead to a more dynamic, engaging, and personalized experience for students. To scale up training a prediction model (such as LSTMs) over large-scale education datasets, we develop a non-parametric approach to cluster symmetric instances in the data. Specifically, we learn a representation based on Node2Vec that encodes symmetries over mastery or skill level since, to solve a problem, it is natural that a student’s strategy is likely to involve concepts in which they have gained mastery. Using this representation, we use DP-Means to group symmetric instances through a coarse-to-fine refinement of the clusters. We apply our model to learn strategies for Math learning from large-scale datasets from MATHia, a leading AIS for middle-school math learning. Our results illustrate that our approach can consistently achieve high accuracy using a small sample that is representative of the full dataset. Further, we show that this approach helps us learn strategies with high accuracy for students at different skill levels, i.e., leveraging symmetries improves fairness in the prediction model.Can Machine Learning Solve the Challenge of Adaptive Learning and The Individualization of Learning Paths? A Field Experiment in An Online Learning Platform
Tim Klausmann, Marius Köppel, Daniel Schunk and Isabell Zipperle
Abstract: The individualization of learning contents with digital technologies promises large individual and social benefits. However, the optimal implementation of individualization remains an open question. To tackle this question we conduct a randomized controlled trial on a large digital self-learning platform. We develop an algorithm based on two convolutional neural networks that assigns tasks to 4,365 learners according to their learning paths. Learners are randomized into three groups: two treatment groups – a group-based adaptive treatment group and an individual adaptive treatment group and one control group. We analyze the difference between the three groups with respect to effort learners provide and their performance on the platform. We do not find differences between our groups. This results light on the multiple challenges associated with the individualization of learning paths.Hierarchical Concept Map Generation from Course Data
John Stamper, Bharat Gaind, Karun Thankachan, Huy Nguyen, Steven Moore
Abstract: Concept maps are a core feature supporting the design, development, and improvement of online courses and educational technologies. Providing hierarchical ordering of the concepts allows for a more detailed understanding of course content by indicating pre- and post-requisite information. In this research, we implement an end-to-end domain-independent system to generate a concept map from digital texts that needs no additional data augmentation. We extract concepts from digital textbooks on the domains of precalculus, physics, computer networks, and economics. We engineer seven relevant features to identify prerequisite relationships between the concepts. These prerequisites are then used to generate and visualize a hierarchical concept map for each course. Our experiments show that the proposed methodology exceeds the existing baseline performance in existing domains including physics and computer networking, by up to 14.5%. Additionally, human evaluation identified four common errors between the prerequisites found through use of the concept maps. Our findings indicate that our methods, which require minimal data preprocessing, can be used to create more informative concept maps. These concept maps can be leveraged by students, instructors, and course designers to improve the learning process in a variety of domains.Leveraging Skill-to-Skill Supervision for Knowledge Tracing
Hyeondey Kim, Jinwoo Nam, Minjae Lee, Yun Jegal, Kyungwoo Song
Abstract: Knowledge tracing plays a pivotal role in intelligent tutoring systems. This task aims to predict the probability of students answering correctly to specific questions. To do so, knowledge tracing systems should trace the knowledge state of the students by utilizing their problem-solving history and knowledge about the problems. Recent advances in knowledge tracing models have enabled better exploitation of problem solving history. However, knowledge about problems has not been studied, as well compared to students’ answering histories. Knowledge tracing algorithms that incorporate knowledge directly are important to settings with limited data or cold starts. Therefore, we consider the problem of utilizing skill-to-skill relation to knowledge tracing. In this work, we introduce expert labeled skill-to-skill relationships. Moreover, we also provide novel methods to construct a knowledge-tracing model to leverage human experts’ insight regarding relationships between skills. The results of an extensive experimental analysis show that our method outperformed a baseline Transformer model. Furthermore, we found that the extent of our model’s superiority was greater in situations with limited data, which allows a smooth cold start of our model.Fair and Skill-diverse Student Group Formation via Constrained K-way Graph Partitioning
Alexander Jenkins, Imad Jaimoukha, Ljubisa Stankovic and Danilo Mandic
Abstract: Forming the right combination of students in a group promises to enable a powerful and effective environment for learning and collaboration. However, defining a group of students is a complex task which has to satisfy multiple constraints. This work introduces an unsupervised algorithm for fair and skill-diverse student group formation. This is achieved by taking account of student course marks and sensitive attributes provided by the education office. The skill sets of students are determined using unsupervised dimensionality reduction of course mark data via the Laplacian eigenmap. The problem is formulated as a constrained graph partitioning problem, whereby the diversity of skill sets in each group are maximised, group sizes are upper and lower bounded according to available resources, and ‘balance’ of a sensitive attribute is lower bounded to enforce fairness in group formation. This optimisation problem is solved using integer programming and its effectiveness is demonstrated on a dataset of student course marks from Imperial College London.ML-SD Modeling: How Machine Learning Can Support Scientific Discovery Learning for K-12 STEM Education
Xiaofei Zhou, Hanjia Lyu, Jiebo Luo and Zhen Bai
Abstract: The importance of machine learning (ML) in scientific discovery is growing. In order to prepare the next generation for a future dominated by data and artificial intelligence, we need to study how ML can improve K-12 students’ scientific discovery in STEM learning and how to assist K-12 teachers in designing ML-based scientific discovery (SD) learning activities. This study proposes research ideas and provides initial findings on the relationship between different ML components and young learners’ scientific investigation behaviors. Results show that cluster analysis is promising for supporting pattern interpretation and scientific communication behaviors. The levels of cognitive complexity are associated with different ML-powered SD and corresponding learning support is needed. The next steps include a further co-design study between K-12 STEM teachers and ML experts and a plan for collecting and analyzing data to further understand the connection between ML and SD.Hey Dona! Can you help me with student course registration?
Vishesh Kalvakurthi, Aparna Varde and John Jenq
Abstract: In this paper. we present a demo of an intelligent personal agent Hey Dona or just Dona with virtual voice assistance in student course registration. It is a deployed project in the theme of AI for education. In this digital age with a myriad of smart devices, users often delegate tasks to agents. While pointing and clicking supersedes the erstwhile commandtyping, modern devices allow users to speak commands for agents to execute tasks, enhancing speed and convenience. In line with this progress, Dona is an intelligent agent catering to student needs by automated, voice-operated course registration, spanning a multitude of accents, entailing task planning optimization, with some language translation as needed. Dona accepts voice input by microphone (Bluetooth, wired microphone), converts human voice to computer understandable language, performs query processing as per user commands, connects with the Web to search for answers, models task dependencies, imbibes quality control, and conveys output by speaking to users as well as displaying text, thus enabling human-AI interaction by speech cum text. It is meant to work seamlessly on desktops, smartphones etc. and in indoor / outdoor settings. To the best of our knowledge, Dona is among the first of its kind as an intelligent personal agent for voice assistance in student course registration. Due to its ubiquitous access for educational needs, Dona directly impacts AI for education. It makes a broader impact on smart city characteristics of smart living and smart people due to its contributions to providing benefits for new ways of living and assisting 21st century education, respectively.MATT: Multimodal Attention Level Estimation for e-learning Platforms
Roberto Daza, Luis Gomez, Aythami Morales, Ruben Tolosana, Julian Fierrez, Ruth Cobos and Javier Ortega-Garcia
Abstract: This work presents a new multimodal system for remote attention level estimation based on multimodal face analysis. Our multimodal approach uses different parameters and signals obtained from the behavior and physiological processes that have been related to modeling cognitive load such as faces gestures (e.g., blink rate, facial actions units) and user actions (e.g., head pose, distance to the camera). The multimodal system uses the following modules based on Convolutional Neural Networks (CNNs): Eye blink detection, head pose estimation, facial landmark detection, and facial expression features. First, we individually evaluate the proposed modules in the task of estimating the student’s attention level captured during online e-learning sessions. For that we trained binary classifiers (high or low attention) based on Support Vector Machines (SVM) for each module. Secondly, we find out to what extent multimodal score level fusion improves the attention level estimation. The mEBAL database is used in the experimental framework, a public multi-modal database for attention level estimation obtained in an e-learning environment that contains data from 38 users while conducting several e-learning tasks of variable difficulty (creating changes in student cognitive loads).Imputing Knowledge Tracing Data with Subject-Based Training via LSTM Variational Autoencoders
Jia Tracy Shen and Dongwon Lee
Abstract: The issue of missing data poses a great challenge on boosting performance and application of deep learning models in the Knowledge Tracing (KT) problem. However, there has been the lack of understanding on the issue in the literature. In this work, to address this challenge, we adopt a subject-based training method to split and impute data by student IDs instead of row number splitting which we call nonsubject based training. The benefit of subject-based training can retain the complete sequence for each student and hence achieve efficient training. Further, we leverage two existing deep generative frameworks, namely variational Autoencoders (VAE) and Longitudinal Variational Autoencoders (LVAE) frameworks and build LSTM kernels into them to form LSTM-VAE and LSTM LVAE (noted as VAE and LVAE for simplicity) models to generate quality data. In LVAE, a Gaussian Process (GP) model is trained to disentangle the correlation between the subject (i.e., student) descriptor information (e.g., age, gender) and the latent space. The paper finally compare the model performance between training the original data and training the data imputed with generated data from non-subject based model VAE-NS and subjectbased training models (i.e., VAE and LVAE). We demonstrate that the generated data from LSTM-VAE and LSTMLVAE can boost the original model performance by about 50%. Moreover, the original model just needs 10% more student data to surpass the original performance if the prediction model is small and 50% more data if the prediction model is large with our proposed frameworks.Optical Character Recognition and Transcription of Berber Signs from Images in a Low-Resource Language Amazigh
Levi Corallo and Aparna Varde
Abstract: The Berber, or “Amazigh” language family is a low-resource North African vernacular language spoken by the indigenous Berber ethnic group. It has its own unique alphabet “Tifinagh” used across Berber communities in Morocco, Algeria, and others. The Afroasiatic language Berber is spoken by 14 million people, yet lacks adequate representation in education, research, web applications etc. For instance, there is no option for “to or from Amazigh / Berber” on Google Translate, which hosts over 100 languages today. Consequently, we do not find specialized educational apps, L2 (2nd language learner) acquisition, automated language translation, and remote-access facilities enabled in Berber. Motivated by this background, we propose a supervised approach called DaToBS: for Detection and Transcription of Berber Signs. The DaToBS approach entails the automatic recognition and transcription of Tifinagh characters from signs in photographs of natural environments. This is achieved by self-creating a corpus of 1862 pre-processed character images; curating the corpus with human-guided annotation; and feeding it into an OCR model via the deployment of CNN for deep learning based on computer vision models. We deploy computer vision modeling (rather than language models) because there are pictorial symbols in this alphabet, this deployment being a novel aspect of our work. The DaToBS experimentation and analyses yield over 92% accuracy in our pilot research. To the best of our knowledge, ours is among the first few works in the automated transcription of Berber signs from roadside images with deep learning, yielding high accuracy. This can pave the way for developing pedagogical applications in the Berber language, thereby addressing an important goal of outreach to underrepresented communities via AI in education.Tracing Changes in University Course Difficulty Using Item-Response Theory
Frederik Baucks, Robin Schmucker and Laurenz Wiskott
Abstract: Curriculum analytics (CA) studies educational program structure and student data to ensure the quality of courses inside a curriculum. Ensuring low variation in course difficulty over time is crucial to warrant equal treatment of individual student cohorts and consistent degree outcomes. Still, existing CA techniques (e.g., process mining/simulation and curriculum-based prediction) are unable to capture such temporal variations due to their central assumption of timeinvariant course behavior. In this paper, we introduce item response theory (IRT) as a new methodology to the CA domain to address the open problem of tracing changes in course difficulty over time. We show the suitability of IRT to capture variance in course performance data and assess the validity and reliability of IRT-based difficulty estimates. Using data from 664 CS Bachelor students, we show how IRT can yield valuable insights by revealing variations in course difficulty over multiple years. Furthermore, we observe a systematic shift in course difficulty during the COVID-19 pandemic.Workshop Description
In this workshop, we invited AIED enthusiasts from all around the world through the following three different channels:
-
First, we invited established researchers in the AIED community to give a broad talk that (1) describes a vision for bridging AIED communities; (2) summarizes a well-developed AIED research area; or (3) presents promising ideas and visions for new AIED research directions.
-
Second, we called for regular workshop paper submissions and cross-submissions (papers that have appeared in or submitted to alternative venues) related to a broad range of AI domains for education.
-
Third, we hosted a global challenge on Codalab for a fair comparison of state-of-the-art Knowledge Tracing models and invited technical reports from winning teams.
Regular Workshop Paper Submission
We invite high-quality paper submissions of theoretical and experimental nature on the broad AIED topics. The workshop solicits 4-7 pages double-blind paper submissions from participants. Submissions of the following flavors will be sought: (1) research ideas, (2) case studies (or deployed projects), (3) review papers, (4) best practice papers, and (5) lessons learned. The format is the standard double-column AAAI Proceedings Style. All submissions will be peer-reviewed. Some will be selected for spotlight talks, and some for the poster session.
Cross-submissions
In addition to previously unpublished work, we invite papers on relevant topics which have appeared in alternative venues (such as other ML or AIED conferences). Accepted cross-submissions will be presented as 15-min oral presentations, with an indication of the original venue. Selection of cross-submissions will be determined solely by the organizing committee. There will be no regular paper reviews for cross submissions. Please use the original paper format when submitting to the cross-submission track.
Submission Website
Submission website: https://easychair.org/conferences/?conf=aaai2023ai4edu. The submission AUTHOR KIT can be found at https://www.aaai.org/Publications/Templates/AnonymousSubmission23.zip.
Global Knowledge Tracing Challenge
In this competition, we would like to call for researchers and practitioners worldwide to investigate the opportunities of improving the student assessment performance via knowledge tracing approaches with rich side information.
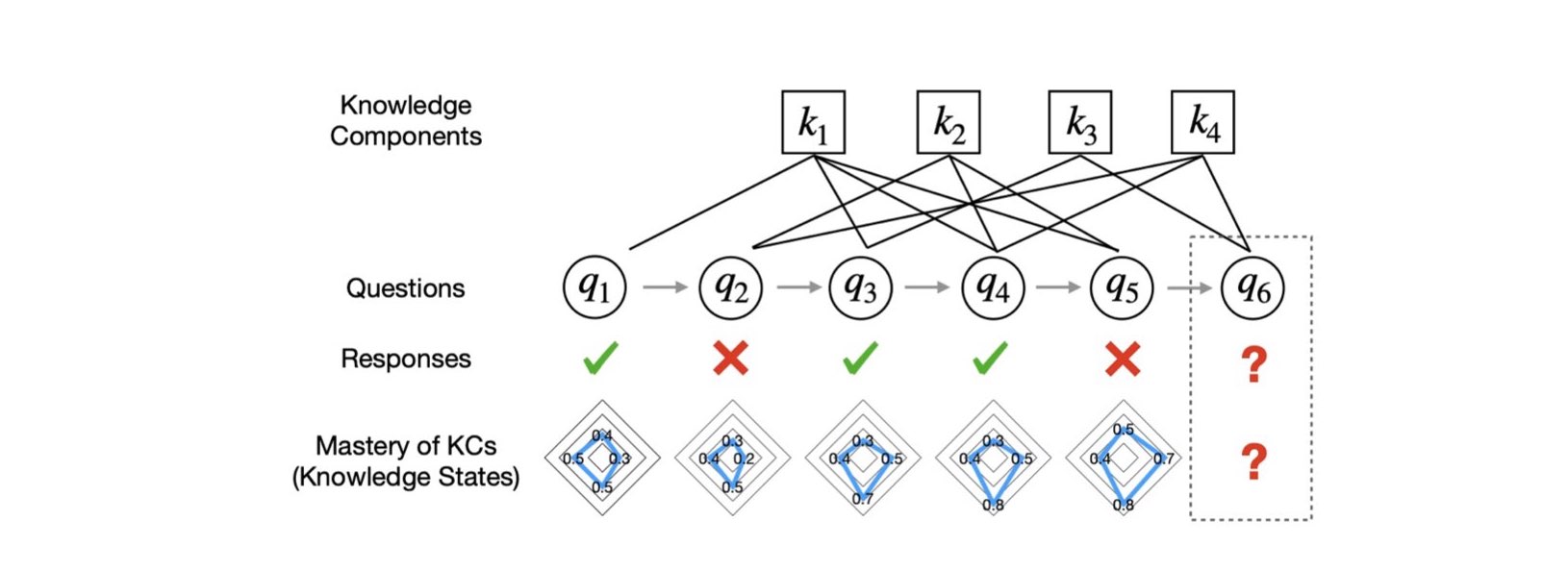
The details of this competition can be found at http://ai4ed.cc/competitions/aaai2023competition.
Important Dates
- Nov 27, 2022: Workshop paper submission due AOE
Dec 25, 2022Jan 01, 2023: Notifications of acceptance- Jan 5, 2023: Deadline of the camera-ready final paper submission
- Feb 13, 2023: Workshop Date
Organizers
- Zitao Liu TAL Education Group & Jinan University, China
- Weiqi Luo Guangdong Institute of Smart Education, Jinan University, China
- Shaghayegh (Sherry) Sahebi University at Albany – SUNY, USA
- Lu Yu Beijing Normal University, China
- Richard Tong IEEE AI Standard Committee & Squirrel AI Learning, USA
- Jiahao Chen TAL Education Group, China
- Qiongqiong Liu TAL Education Group, China


{kind=link}